《玩游戏的人工智能模型:学习根据口头指导行动》
游戏AI模型已存在数十年,但通常专注于一款游戏并始终以获胜为目标谷歌深度学习研究人员采用了不同的方法
“`html
谷歌的DeepMind训练AI成为您在视频游戏中的合作伙伴!
玩游戏的AI模型已经存在几十年了,但它们通常只能专门针对一款游戏,并始终努力取得胜利。然而,谷歌DeepMind的研究人员采取了一种不同的方法,推出了他们最新的创造——一个不仅学会像人类一样玩多个3D游戏,还尽力理解并根据口头指导行动的模型。
在大多数游戏中,已经有可以执行类似操作的AI或电脑角色,但它们通常通过正式的游戏内命令间接控制。DeepMind的新模型名为SIMA(可扩展的可指导多世界代理),它摆脱了这种方法。SIMA并没有访问游戏的内部代码或规则,而是在人类玩家的无数小时游戏视频录像片段上接受训练。通过这些数据,模型学会将特定的行动、对象和互动的视觉表示与通过数据标注者提供的注释关联起来。研究人员还录制了玩家相互指导在游戏中执行任务的视频。
例如,模型可能会学习到屏幕上特定的像素移动模式对应于“向前移动”的动作。同样,当角色接近类似门的物体并使用类似门把手的物体时,它会认识到这是“打开”一个“门”。这些是需要几秒钟时间但不仅仅需要按键或识别某些东西的简单任务或事件。
训练视频来自不同游戏,从Valheim到Goat Simulator 3都有涉及。这些游戏的开发人员参与并同意使用他们的软件。研究人员的主要目标之一是确定训练一个能玩一组游戏的AI模型是否能让它有能力玩它之前从未见过的其他游戏——这个过程被称为泛化。
答案是肯定的,但带有一些警告。在多个游戏上训练的AI代理在未接触过的游戏上表现更好。然而,重要的是需要注意,许多游戏融入了可能会对即使是做好准备的最佳AI都构成挑战的特定机制或术语。尽管如此,模型可以通过足够的训练数据学会这些细微差别。
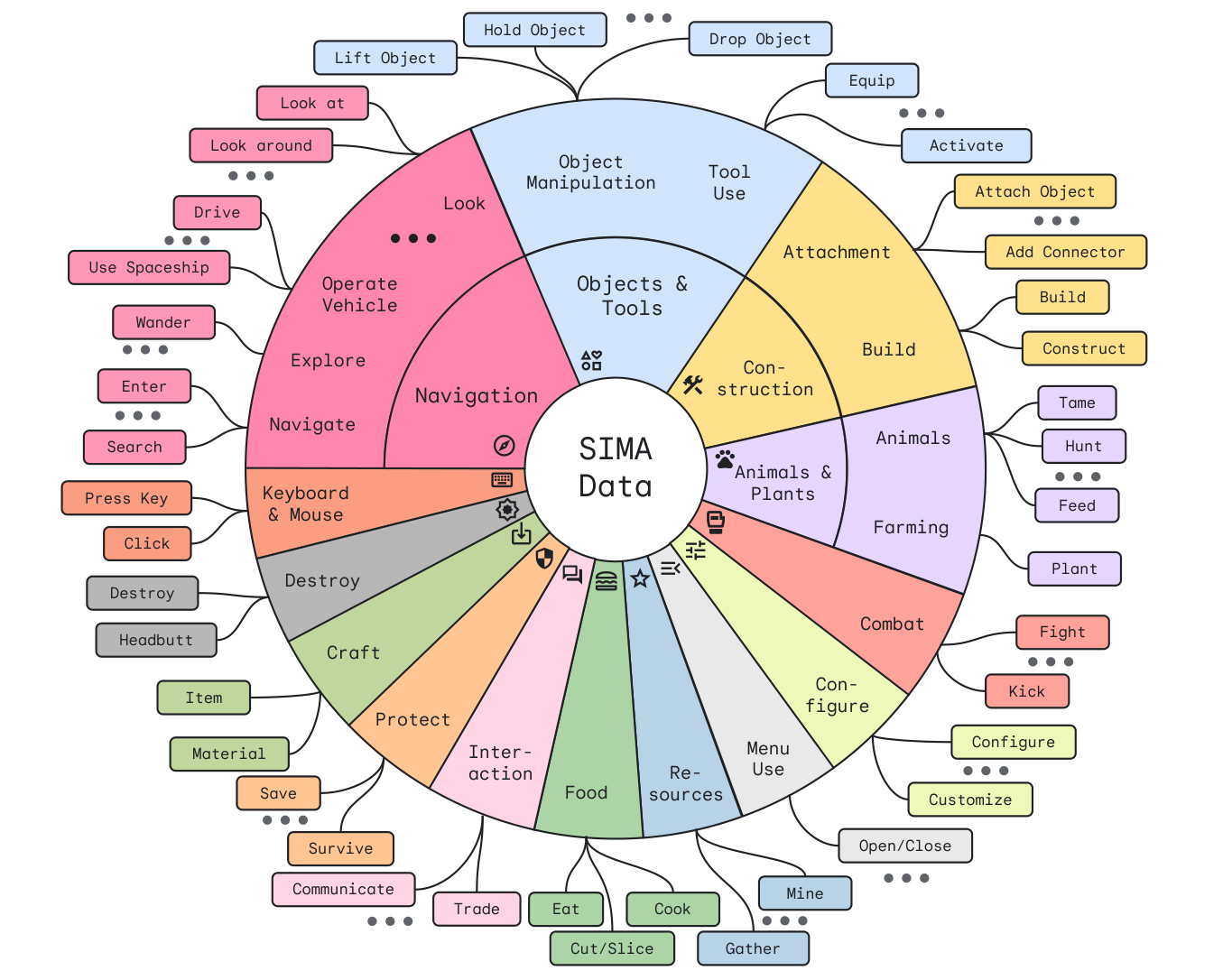
有趣的是,尽管游戏术语变化多样,但玩家拥有的“动词”数量有限,这些动词显著影响游戏世界。无论您是搭建临时住所、搭起帐篷还是召唤魔法庇护所,您本质上都是在“建造房屋”。该地图展示了SIMA代理目前认识的几十种基本动作,揭示了它是如何解释游戏内各种行动的:
🏢 建造房屋 🛡 防御 🍌 收集资源 ✈ 旅行
研究人员的抱负,除了推动基于代理的AI之外,还是创造一个比今天的刚性、硬编码伙伴更自然的游戏伙伴。玩家不再需要与超人类AI竞争,而是可以有着协作性并对口头指导做出响应的SIMA玩家。因为SIMA玩家只看到了游戏屏幕上的像素,他们学会了以与人类类似的方式执行任务。这使他们能够适应并发展新的行为。
🤖💬 想知道AI如何改变各个行业?观看这个视频以了解AI在实际应用中的更多应用: 开放式协作与创造 👈
现在,您可能想知道这种方法与常用于构建代理型AI的模拟器方法相比如何。在模拟器方法中,大部分无人监督的模型在一个3D模拟世界中进行实验,凭直觉学习规则并根据这些规则设计行为。然而,这种方法需要游戏或环境提供的奖励信号让代理可以学习。在许多商业游戏中,这种信号并不可获得。此外,研究人员对训练能够执行多种以开放文本描述的任务的代理感兴趣,这种方法使用从人类行为中学习的模仿学习,其中目标以文本格式提供。
该方法允许代理追求更广泛的目标,因为它不受严格的奖励结构限制。代理不再仅仅受分数或胜负结果的影响,而是可以被训练去重视更抽象的标准,比如它们的行为与以前观察到的行为的相似性。因此,它们可以被训练“希望”执行几乎任何任务,只要训练数据以某种方式表现它。
“““html
其他公司也在探索类似的举措。游戏中的NPC正被视为利用大型语言模型(LLMs)作为聊天机器人的潜在机会。此外,AI研究正在探索模拟和跟踪简单的即兴动作或互动,从而产生引人入胜的代理行为的发展。例如,研究人员已成功用AI填充了一个小虚拟城镇,导致了融洽的互动和一种社区感。
🏡👥 想了解用AI填充的虚拟城镇吗?在这篇文章中阅读更多信息:Researchers Populated a Tiny Virtual Town with AI (and It Was Very Wholesome)
最后,正在进行探究无限游戏(如MarioGPT)的实验,探讨AI代理在玩具有无限可能性的游戏中的潜力。然而,这是另一个讨论的话题。
总之,DeepMind的SIMA模型代表了AI游戏玩家代理领域的重大进展。通过训练模型从人类游戏中学习并对口头指令做出反应,研究人员不仅在推动AI的界限,还在努力创造更自然、合作和互动的游戏伙伴。随着AI的不断发展,我们可以期待看到跨越各个行业和娱乐形式的新颖和令人兴奋的应用。
问答
Q: 多个游戏上训练的AI模型能有效地玩从未见过的游戏吗?
A: 是的,经过多个游戏训练的AI代理显示出在未接触过的游戏中表现良好的能力。然而,个别游戏中的特定机制或术语可能会对AI模型构成挑战。在有足够的训练数据的情况下,模型可以克服这些挑战。
Q: SIMA模型如何学习理解游戏中的口头指令?
A: SIMA模型是在人类玩游戏的视频素材的基础上训练的,同时还有数据标注人员提供的注释。通过将动作、物体和互动的视觉表示与口头指令关联起来,模型学会理解并执行这些指令。
Q: SIMA的训练如何不同于传统基于模拟器的代理训练?
A: 传统基于模拟器的代理训练依赖于强化学习,需要来自游戏或环境的奖励信号。然而,SIMA的训练方法侧重于模仿从人类行为学习,使用开放式文本目标而不是特定奖励信号。这使模型能够追求更广泛的任务和目标。
Q: 除了玩游戏和理解游戏外,AI在游戏中还有其他应用吗?
A: 当然有!AI在游戏中有许多应用,包括NPC行为、真实的物理模拟、识别游戏内命令的语音识别等。AI技术不断发展,增强着游戏体验的各个方面。
📚 参考资料: – DeepMind’s Agent57 AI agent can best human players across a suite of 57 Atari games – Researchers Populated a Tiny Virtual Town with AI (and It Was Very Wholesome) – Open-Ended Collaboration and Creation (视频)
对于能够像人类一样玩游戏并对口头指令作出反应的AI模型,您有什么看法?您认为这项技术有可能彻底改变游戏行业吗?在下方评论中分享您的观点!别忘了与您的朋友在社交媒体上分享这篇文章!🎮🤖✨
“`






